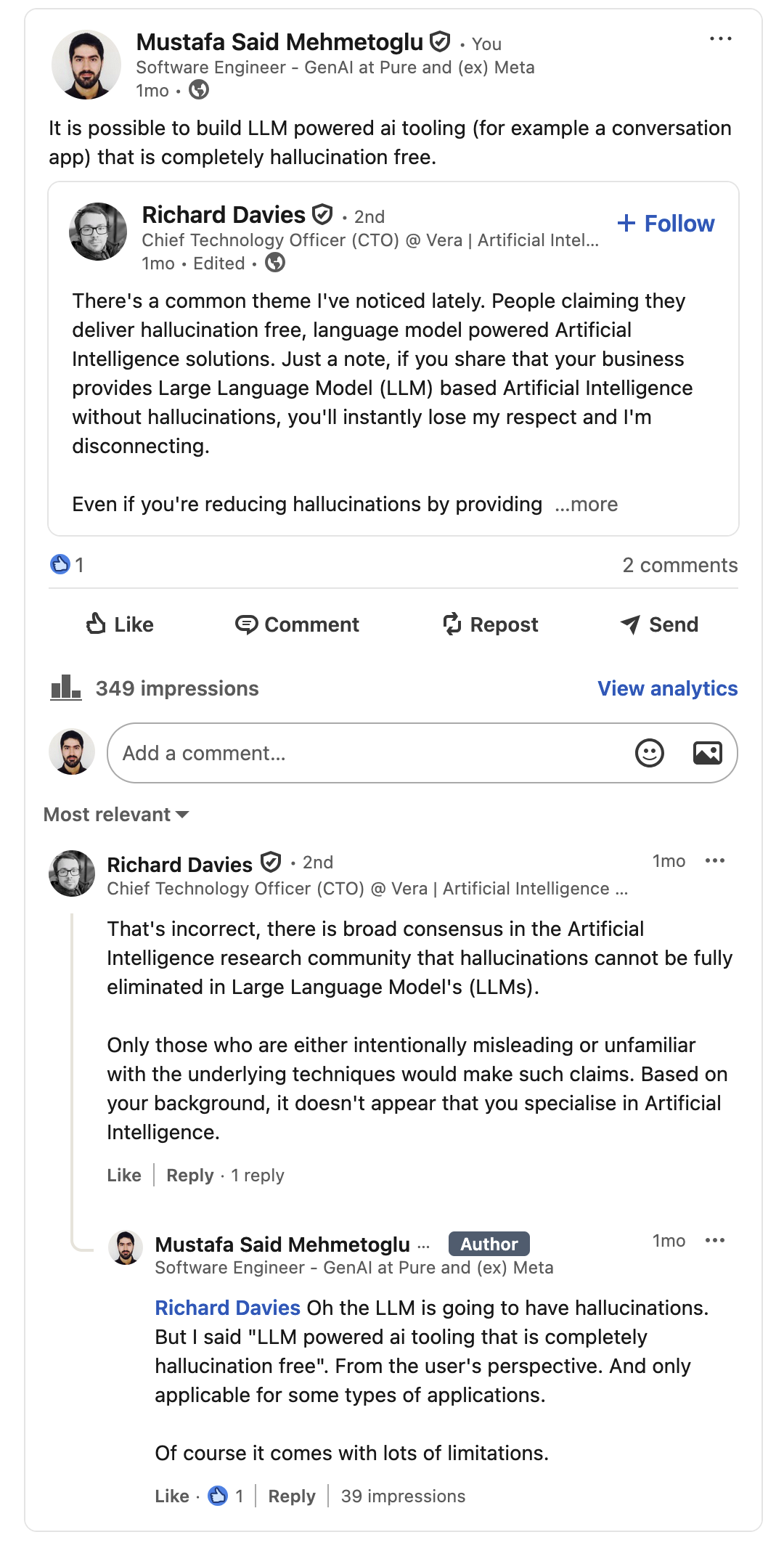
I recently had an exchange on Linkedin where I claimed that a hallucination free AI solution powered by LLMs is possible. A nice gentleman kindly pointed out that I had no idea what I was talking about :)
Luckily, I do have some experience with GenAI to have an idea of the concept (given that I am part of the team developing AI Copilot by Pure Storage), and I will explain my idea here. But first, let me clarify a few important points.
Disclaimer: This post is not about the AI Copilot by Pure Storage, this is just my personal blog. All views and suggestions here are my own, and do not represent my employer or any current project.
Clarifications
- Hallucination: Hallucination refers to the generation of false or misleading information that is not grounded in reality. It is a well-known issue with LLMs, and it can lead to serious problems in applications that rely on LLMs to generate responses.
- LLMs will always hallucinate: I agree that LLMs will always hallucinate, but this does not mean that we cannot build applications that are hallucination free from the user’s perspective. That is, the application will not present any false information to the user.
- Absolutely No Hallucination: There are approaches out there that will reduce hallucination, such as always trying to add relevant context to the LLM prompt (e.g. RAG), adding a second check on the final response, and so on. However, these approaches will not guarantee that the final response is free of hallucination. In our design we are aggressively going after hallucinations at the expense of flexibility.
- Limitations: As I will explain, there are several limitations to this approach, and it is not suitable for all products. For instance, I don’t think it is suitable for a coding assistant like Github Copilot.
- Not A Coding Tutorial: I may provide snippets of code or pseudo code in this post, but this is not a coding tutorial. This is a high-level design discussion.
The Product
Let’s first describe the product we are going to design.
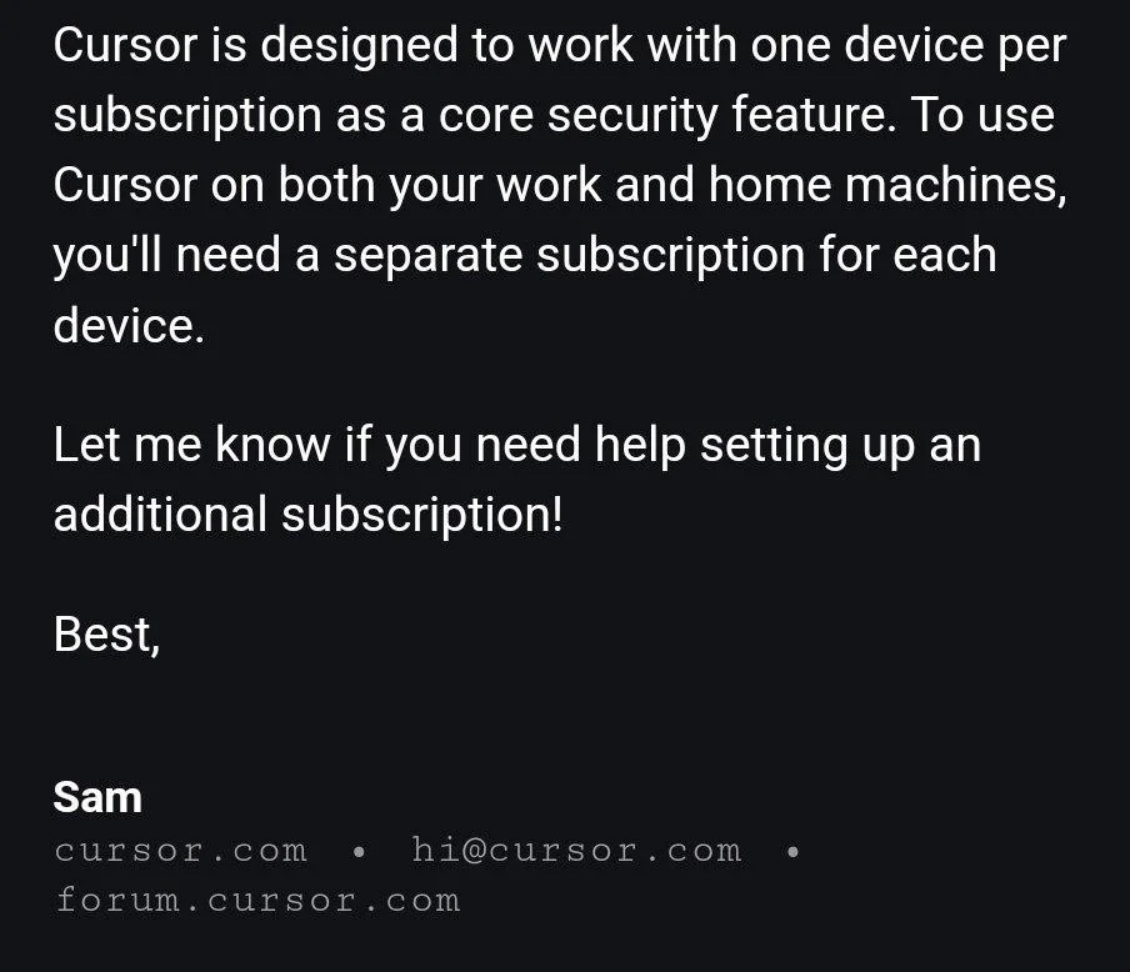
Recently, Cursor Company (makers of the popular AI coding assistant) made headlines when a subscriber sent a question to their support team, and received a reply that was generated by AI. The reply cited a policy that did not exist. It was a hallucination, and it cost the company money as many users canceled their subscriptions. It was not indicated that the response was generated by AI.
So let’s design an AI support agent that will never hallucinate. The agent will be able to answer questions based on the company’s policies, documentation as well as user’s account information. Let’s assume the main interaction is through email, so our agent doesn’t have to be very conversational. The agent will be able to answer questions like:
- “What is the refund policy?”
- “How do I install the software?”
- “I have run into this problem … what should I do?”
- “What is my current subscription plan?”
- “What is my recent bill amount?”
The First Steps
The core idea is to generate the final response using deterministic software components, rather than relying on the LLM to generate the final response. The LLM will be used as an orchestrator to make tool calls for gathering and processing the necessary information, and it will call final response tools which will generate our email response.
Our first tool generates a response from Company policies and documentation. It is almost a RAG ( Retrieval-Augmented Generation ) tool, but you will see an essential difference: we will not return the retrieved documents to the LLM, we will directly send them (or maybe links to them) to the user. Let’s call it generate_document_response. Let’s number the company documents, and the LLM can call this tool with a number to get a response generated.
| Number | Document |
|---|---|
| 1 | Refund policy: … |
| 2 | Cancellation policy: … |
| 3 | Setup Instructions: … |
| … | … |
Pseudo code for the tool:
def generate_document_response(document_number):
# Tool description includes document number mapping
documents = {
1: "Refund policy: ...",
2: "Cancellation policy: ...",
3: "Setup Instructions: ..."
...
}
return FinalAnswer.add(documents[document_number], answer_type="document")
Next, we need a tool to generate a response for the user’s account information. Let’s call this tool generate_account_response. This tool will gather the user’s account information and generate a response.
def generate_account_response(requested_account_info):
# Tool description includes account info mapping
account_info = get_user_account_info()
if requested_account_info == "subscription_info":
response = f"Your current subscription information is {account_info['subscription_info']}."
elif
...
return FinalAnswer.add(response, answer_type="account info")
Let’s assume the FinalAnswer is a class that is used to combine the responses, add a greeting on top, and return the final response to the user and end the chain of execution.
class FinalAnswer:
def generate_answer():
answer = f"Hello {user_name}.\n"
for call in FinalAnswer.calls:
if call[answer_type] == "document":
response += f"Here is a document from our website you may find helpful: {call[response]}"
elif
...
# email answer to user
We can have a context like the following (kept short for brevity) for the LLM:
context = "You are an AI support agent. You can answer questions about the company's policies, documents, and user's account information. You will use the generate_document_response tool to generate responses from company documents, and the generate_account_response tool to generate responses from user's account information. You will never generate a final response yourself, you will call these tools which will generate the final response for you."
Now, if the user asks a question such as “Can I get a refund for my last month’s subscription?”, the LLM will recognize that this question is related to the refund policy and user’s subscription information. It will call the generate_document_response tool with the document number for the refund policy, and the generate_account_response with subscription_info.

But clearly, our response is not a direct answer the question, it will be up to the user to read the refund policy and see if they are eligible for a refund. This brings us to a major limitation of this approach.
Limitation: Limited Flexibility: In this approach, the writing of our responses is limited by the flexibility of our final response tooling.
Always Include All Relevant Data In Final Response
Let’s say we want to be able to answer questions like “How much have I spent on my subscriptions so far?”, “How much have I spent monthly this year?”, etc. We can add a tool to generate a response based on the user’s spending history and an aggregation function. Let’s call this tool generate_spending_response.
def generate_spending_response(time_period, aggregation=None):
# Tool description includes time period and aggregation options
spending_history = get_user_spending_history(time_period)
if aggregation:
if aggregation == "average":
average = compute_aggregate(spending_history, "average")
response = f"You have spent an average of {average} in the time period {time_period}."
elif aggregation == "total":
...
response = "Here is your spending history for the time period {time_period}: {spending_history}."
return FinalAnswer.add(response, answer_type="spending info")
Do note that we are including the time period as part of our answer. This is important, as the LLM might have made a mistake in interpreting the user’s question, or in using the correct time period. We don’t want the answer to be misinterpreted, so we include all the details for the user to see.
Important Note: It is crucial to include all relevant data in the final response, including all tool parameters, in an appropriate way. This way, the user can see what data was used to generate the response.
Query - Answer Mismatch
Note that we do not guarantee that the final response will satisfy the user’s question, but we guarantee that the final response will be factually correct within itself. For example, if the user asks “What should I do with my card payment problem?” and the LLM interprets this as asking about refund policy, the agent will end up responding with the refund policy, which may not be what the user wanted to know. Or, say the user asks “What is my highest spending last year?” but our tooling does not directly support this question. The agent might just return the list of spending amounts for the year. The user will have to read the list and find the highest spending themselves.
Limitation: Query - Answer Mismatch: The answer may not satisfy the user’s question, it may provide useful data or completely irrelevant data. However, it will be factually correct. The user will have to read the response and decide if it is relevant to their question. This is a deliberate trade-off for correctness over convenience.
For another example, let’s say the user’s question was “How much have I spent on my subscriptions last year?”, but the LLM incorrectly called the tool with the time period “year=2023” (even though the user probably meant 2024). The final response will still include the time period, so the user can see that the answer is using data from 2023. But what if the user doesn’t pay attention to the time period detail? In this case the user will misunderstand the response, assuming the number they see is for the year 2024 since that was their question. This brings us to another limitation/UX risk of this approach.
Limitation: UX Risk: The LLM is not guaranteed to call the correct tool with the correct parameters. Although we can ensure all relevant data is included in the final response, the user might still be misled simply because they may not read the final response carefully and notice the incorrect details. From a user perspective, this may be interpreted as inaccurate information.
Sequential Tool Calls
We will now move on to a more sophisticated system, by doing multiple sequential tool calls. This will increase flexibility of our responses, as well as extendability to more use cases or type of questions.
For instance, what if we also have token usage history, number of queries, etc. and we want to apply the aggregation function to all of these numerical data? What if we want to be able to use spending data in other ways? Let’s refactor our generate_spending_response function and separate getting the spending data step and the aggregation step into 2 separate functions. Let’s have a tool that can apply the aggregation function to any numerical data and call it apply_aggregation. Here is an example execution flow with this new design:

However, this design is flawed, in the sense that it doesn’t meet our requirement of never hallucinating. Can you spot the problem?
Click to See The Hallucination Risk

The problem is that the LLM is passing the spending data to the aggregation function, which is not guaranteed to be correct. The LLM can hallucinate within the spending data, it might miss values or make up values. The aggregation function will then compute the average based on this hallucinated data, and the final response will be incorrect.
To fix this, we can change the design so that the LLM does not pass the data to the aggregation function, but rather just a pointer to the spending data. The aggregation function will then retrieve the data itself using the pointer, and compute the average based on the actual data. This way, the LLM cannot hallucinate within the data.

Final Thoughts
This design allows us to build an AI support agent that never hallucinates, while still being able to answer complex questions. The LLM is used as an orchestrator to gather the necessary information, pass pointers to data around, and call final response tools. We can design more sophisticated tooling to increase the coverage and flexibility of the responses. For example, we can add response formatting tools that can format the response in certain ways, such as generating a table, sorting the data etc. For unsupported questions, the LLM can call an escalation tool to pass the case to a human agent.
We traded off flexibility for correctness, and this is a deliberate design choice. I do believe that this trade-off is acceptable, in fact absolutely necessary, for many applications, such as medical advice, legal advice, tax return assist etc. Customer support applications too, considering Cursor’s trouble. In these applications, it is crucial that the information provided is factually correct. If no information is provided at all due to limitations of the tooling, the user can still find other ways to get the information they need (or the agent can escalate to human support). For example, a doctor can check if medical AI assistant can provide any relevant information, and if not, they can consult medical literature like they normally would.
Leave a Comment
Your email address will not be published. Required fields are marked *